

序章:Pythonとscikit-learnで始める機械学習
2025年現在、Pythonは機械学習分野で最も広く使われる言語です。理由はシンプルな文法と豊富なライブラリ。初学者でも学びやすく、データ分析からモデル構築まで必要なツールが揃っています。
代表ライブラリは scikit-learn・TensorFlow・PyTorch。特にscikit-learnは、前処理→学習→評価→チューニングを一貫して実装でき、入門に最適です。日本でも学習需要が高く、オンライン講座(例:Aidemy Premium)が人気です。
第1章:Pythonとscikit-learnのセットアップ
Pythonのインストール
最新の安定版はPython 3.13系(パフォーマンス改善や新機能が多数)。初学者にも推奨です。
インストール手順
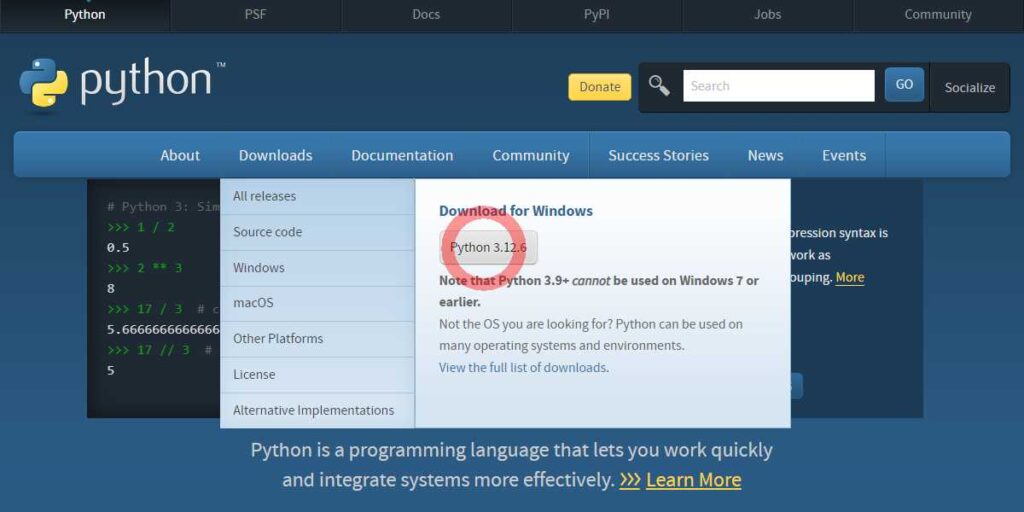
- 公式サイト:python.org から最新をDL。
- インストーラ選択:「Download Python 3.13」をクリックしOS用を選択。
- セットアップ:「Add Python to PATH」に必ずチェック→Install。
- 確認:
python --versionが 3.13.x を返せばOK。
仮想環境のセットアップ

仮想環境の作成と有効化
- 作成:
python -m venv myenv - 有効化:
- Windows:
myenv\Scripts\activate - macOS/Linux:
source myenv/bin/activate
有効化されるとプロンプト先頭に
(myenv)が表示されます。 - Windows:
scikit-learnのインストール
pip install scikit-learn動作確認:
import sklearn
print(sklearn.__version__)開発環境の選定
- Jupyter Notebook:探索・記録に最適。
- Visual Studio Code:拡張機能が豊富、Git/デバッグが楽。
- PyCharm:静的解析・補完が強力なIDE。
第2章:ワークフローとデータ前処理の基本
機械学習の標準フロー
- データ取得
- 前処理(欠損/外れ値/エンコード/スケーリング)
- モデル選択
- 学習(train)
- 評価(test/validation)
- ハイパーパラメータ調整
- 保存・デプロイ
欠損値の処理(SimpleImputer)
欠損を放置すると学習や推論で失敗します。平均や最頻値などで補完:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="mean")
data_imputed = imputer.fit_transform(data)スケーリング(StandardScaler)

多くのモデルでスケール差は不利に。標準化で平均0・標準偏差1へ:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data_imputed)モデル選択とトレーニング
タスクは大きく 回帰 と 分類 に分かれます。
回帰(例:線形回帰)
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)分類(例:ロジスティック回帰)
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)モデル評価
回帰は MSE と R²、分類は Accuracy や 混同行列 を使用。
回帰モデルの評価
from sklearn.metrics import mean_squared_error, r2_score
y_pred = model.predict(X_test)
print("MSE:", mean_squared_error(y_test, y_pred))
print("R² :", r2_score(y_test, y_pred))分類モデルの評価(混同行列をMatplotlibで可視化)
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
y_pred = clf.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots()
im = ax.imshow(cm)
ax.set_xlabel("Predicted"); ax.set_ylabel("Actual")
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, cm[i, j], ha="center", va="center")
plt.title("Confusion Matrix")
plt.show()第3章:実践例—scikit-learnでシンプルな回帰モデル
公開の気象データ等を用いて、前処理→学習→評価→可視化までを体験します。
データ読み込み
import pandas as pd
data = pd.read_csv("japan_weather_data.csv") # 例:気象庁の公開CSV前処理と学習
欠損補完・標準化の後、学習データでモデルを訓練し、テストで評価します。
予測の可視化(実測 vs 予測)
import matplotlib.pyplot as plt
plt.scatter(y_test, y_pred)
plt.xlabel("Actual"); plt.ylabel("Predicted")
plt.title("Actual vs Predicted")
plt.show()第4章:パイプラインとハイパーパラメータ最適化
Pipelineで前処理〜学習を一括
前処理とモデルを一つのオブジェクトで管理でき、リーク防止・再現性向上に有効。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
pipeline = Pipeline([
("scaler", StandardScaler()),
("regressor", LinearRegression())
])
pipeline.fit(X_train, y_train)GridSearchCVでハイパーパラメータ最適化
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import Ridge
param_grid = {"alpha": [0.01, 0.1, 1, 10, 100]}
grid = GridSearchCV(Ridge(), param_grid, cv=5, n_jobs=-1)
grid.fit(X_train, y_train)
best = grid.best_estimator_最終章:まとめと次のステップ
scikit-learnで前処理→学習→評価→最適化までを通しで体験しました。ここからは、ディープラーニングや生成AIなども視野に入れて学習を拡張しましょう。
入門は「小さく作って評価する」の反復が最短ルートです。継続で“精度と再現性”を積み上げていきましょう。
AI・機械学習の学習を考えているなら、Aidemy Premiumが最適です。
短期で要点を押さえるコースから始めてみましょう。
![]()
スポンサーリンク




