
AIとPythonプログラミングの基礎:初心者が知るべきポイント
AI(人工知能)とPythonは、ビジネスから日常まで幅広く活用されています。AIは学習と意思決定を担い、Pythonは読みやすい構文と豊富なライブラリでAI開発に最適な言語です。初心者でもPythonを用いれば短期間で基礎を身につけやすく、本稿では要点と学び方を整理します。
第1章:AIプログラミングの基礎知識
まずはAIの基本概念を押さえましょう。AIは「人のように学習・推論し問題解決を行う」技術群です。主な分野は次の三つです。
- 機械学習(Machine Learning):過去データから学び、予測・分類を行う(例:スパム判定、レコメンド)。
- ディープラーニング(Deep Learning):多層ニューラルネットで複雑なパターンを学ぶ(例:画像・音声認識、自動運転)。
- 自然言語処理(NLP):人間の言語を理解・生成(例:翻訳、音声アシスタント、チャットボット)。
重要用語:モデル(タスクを解くアルゴリズム)、トレーニング(データで学習)、テスト(性能評価)、データセット(学習/評価用データ)。この全体像を掴んだら、実装の土台となるPythonに進みます。
第2章:Pythonプログラミングの基本

Pythonは直感的な構文と強力な標準/外部ライブラリが魅力です。動的型付けで柔軟に書け、データ処理・数値計算・可視化まで一通り揃います。基礎要素は以下です。
- 変数とデータ型:
int/float/str/boolなど。
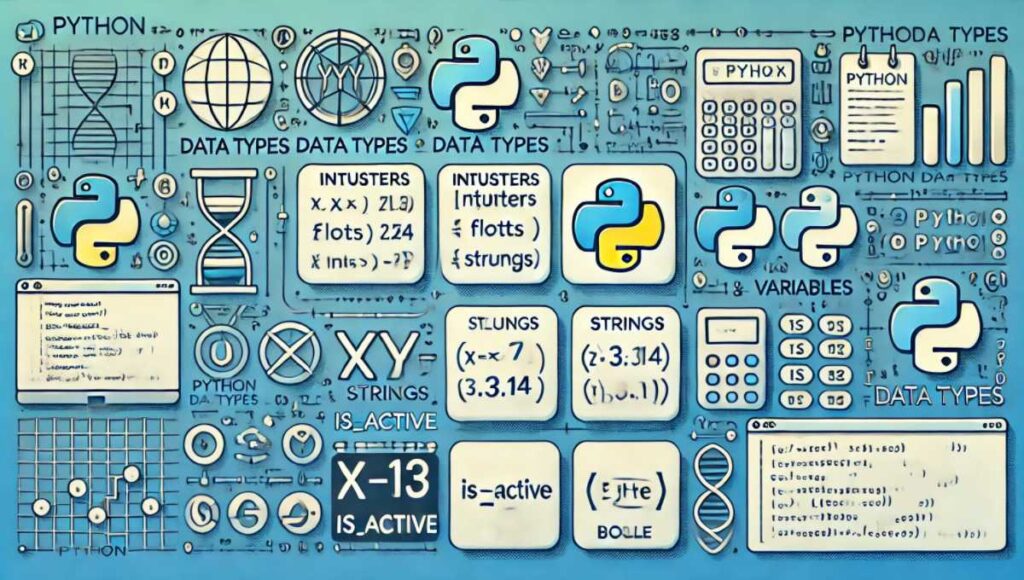
x = 10 # 整数
y = 3.14 # 浮動小数点
name = "AI" # 文字列
is_active = True # ブール値
- 制御構造:
if/for/whileで分岐・反復を記述。
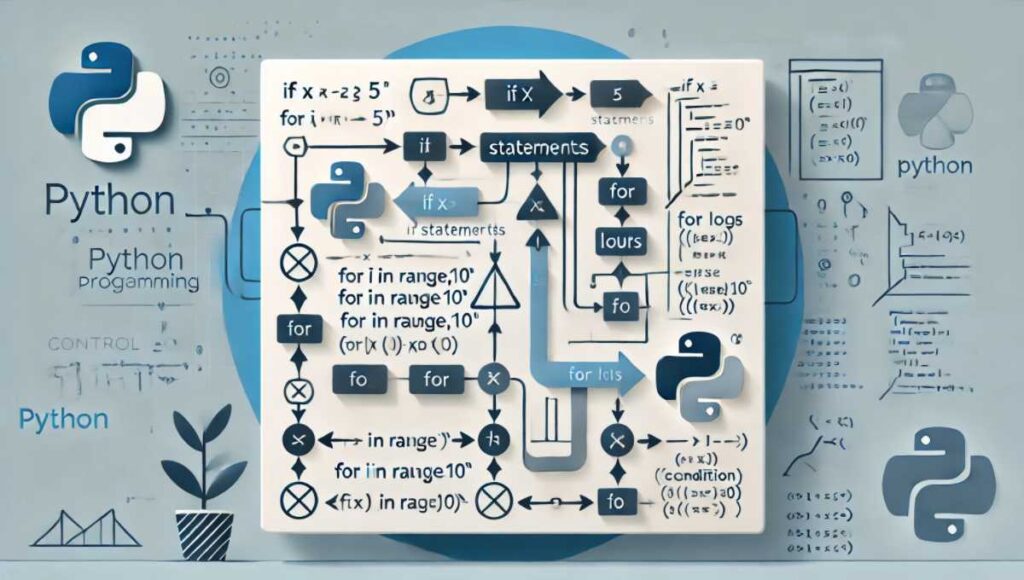
if x > 5:
print("xは5より大きい")
else:
print("xは5以下です")
- 関数定義:再利用可能な処理を
defで切り出し。
def greet(name):
return f"こんにちは、{name}さん!"
print(greet("AIプログラミング"))
- ライブラリ活用:数値計算
NumPy、データ解析pandas、機械学習scikit-learn、深層学習TensorFlow/PyTorchなど。
NumPyの行列演算例:
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(a + b) # [5 7 9]
基礎が固まったら、PythonでAIモデルを作る実践へ進みます。
第3章:PythonでAIプログラミングを始める方法

最初の一歩として、基本的な回帰モデル(線形回帰)を実装してみます。
1. 線形回帰の最小例(scikit-learn)
# 必要なライブラリをインポート
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import numpy as np
# データセット(y = x)を作成
X = np.array([[1], [2], [3], [4], [5]]) # 特徴量
y = np.array([1, 2, 3, 4, 5]) # 目標値
# 学習/テスト分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 学習
model = LinearRegression()
model.fit(X_train, y_train)
# 予測と評価
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"予測値: {y_pred}, 平均二乗誤差: {mse:.4f}")
データ分割→学習→予測→評価という基本フローを体験できます。
2. 分類:SVMでIrisを分類
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# データ読み込み
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 学習
svm = SVC(kernel='linear', random_state=42)
svm.fit(X_train, y_train)
# 予測と精度
y_pred = svm.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"予測精度: {acc:.3f}")
3. データ分析の基礎とpandas
モデル精度はデータ前処理に大きく依存します。読み込み・要約・抽出を手早く行えるpandasは必須です。
import pandas as pd
# CSV読み込み
data = pd.read_csv('sample_data.csv')
# 概要統計
print(data.describe())
# 列の抽出
column_data = data['column_name']
print(column_data.head())
第4章:オンライン学習リソースの活用

1. Aidemy Premium / TechAcademy の活用
Aidemy Premium:Python基礎から機械学習・DL・NLPまで実践演習とメンター支援。
TechAcademy:現役エンジニアのメンタリングでAI/DS/WEBを横断的に学習。
2. 効率的なオンライン学習の進め方
- 計画を立てる:週次の学習量・演習時間を具体化。
- 実践重視:講義+コード演習で定着。
- 質問する:疑問は即解消(メンター/掲示板)。
- コミュニティ活用:相互支援で継続と視野拡大。
3. 無料で学べる教材
- YouTubeチャンネル:視覚的に理解を深める。
- 公式ドキュメント/チュートリアル:Python・scikit-learn・TensorFlowなど。
- オープンコースウェア:大学レベルの無料講義で基礎を強化。
第5章:まとめと今後の学習ステップ

1. 本稿の要点
AIの基礎(ML/DL/NLP)と開発言語Pythonの役割、そしてデータ処理→学習→評価の一連の流れを確認しました。主要ライブラリ(scikit-learn / TensorFlow / PyTorch)の存在も把握できたはずです。
2. 次の一歩
- 小規模プロジェクト:予測/分類/画像認識など具体的な題材で実装。
- 数学の補強:線形代数・確率統計・最適化。
- OSS参加:GitHubで実践経験とレビューを得る。
- 専門書/論文:最新技術・理論の理解を深める。
3. 継続学習のコツ
- 毎日少しでも手を動かす:習慣化で定着。
- 未知に挑戦:難しい題材にもトライ。
- コミュニティ参加:情報獲得とモチベ維持。
自分のペースで学びを継続し、実装経験を積み重ねていきましょう。




